

From Underdog to Top Contender: How I Surpassed 76% of Teams on Kaggle with Machine Learning Methods
Mastering Algorithm Selection, Time Series Prediction, and Unleashing the Untapped Power of the Extra Trees


Hello, Legends! It's Neokai here, thrilled to present the second issue of our Newsletter, Hustle Data. I've received valuable feedback from my friend Cyall on improving our opening paragraph, and I'm excited to implement those changes. I want to emphasize that I'm a passionate learner, and this whole experience is a new frontier for me. So, please don't hesitate to share your suggestions and feedback—I'm eager to learn and grow from it all.
In today's Hustle Data issue, I'll share my journey in a Kaggle competition, where I achieved a remarkable top 24% ranking just by sticking to the basics of machine learning. Despite my initial hesitation and fears of embarrassment, I finally took the leap and participated in the GoDaddy competition on Monthly Microbusiness Density Forecasting across various states and counties in the United States. With my passion for time series forecasting and the valuable feedback I received from my peers in an Advanced Statistical Investigation class, I seized this opportunity to dive into the world of Kaggle and showcase my skills. Let's dive into the thrilling details of my journey!
Kaggle Competition Introduction
Platform: Kaggle
Hosted by: GoDaddy
Objective: Monthly Microbusiness Density Forecasting across states and counties in the United States
Focus: Time-series forecasting (Check this youtube video if you are not aware of Time Series Forecasting)
Rank: Top 24%
Overview
This competition aims to develop an accurate model that predicts monthly microbusiness density in specific areas using U.S. county-level data. The competition is hosted by GoDaddy, the world's largest services platform for entrepreneurs, aiming to empower microbusiness owners and provide policymakers with valuable insights to support these small enterprises.
Micro-businesses, defined as businesses with an online presence and ten or fewer employees, have become a growing trend in the American economy. They are often too small or new to be captured in traditional economic data sources, making it challenging for policymakers to understand their impact and implement effective policies and programs to support them. GoDaddy, through its Venture Forward team, has gathered data on over 20 million micro-businesses, owned by more than 10 million entrepreneurs, and aims to leverage this data to bridge the information gap.
Current models used in this field rely on internal and census data, applying econometric approaches to identify the primary determinants of micro-business success. However, there is a need to incorporate additional data sources and advanced methodologies to enhance predictions and provide policymakers with comprehensive insights.
DATASET DESCRIPTION
The data available that was available in the competition is as follows: Dataset Link
Train.csv
row_id- An ID code for the row.cfips- A unique identifier for each county using the Federal Information Processing System. The first two digits correspond to the state FIPS code, while the following 3 represent the county.county_name- The written name of the county.state_name- The name of the state.first_day_of_month- The date of the first day of the month.microbusiness_density- Microbusinesses per 100 people over the age of 18 in the given county. This is the target variable. The population figures used to calculate the density are on a two-year lag due to the pace of updates provided by the U.S. Census Bureau, which provides the underlying population data annually. 2021 density figures are calculated using 2019 population figures, etc.active- The raw count of micro-businesses in the county. Not provided for the test set.
Sample_submission.csv
A valid sample submission. This file will remain unchanged throughout the competition.
row_id- An ID code for the row.microbusiness_density- The target variable.
Test.csv
Metadata for the submission rows. This file will remain unchanged throughout the competition.
row_id- An ID code for the row.cfips- A unique identifier for each county using the Federal Information Processing System. The first two digits correspond to the state FIPS code, while the following 3 represent the county.first_day_of_month- The date of the first day of the month.
revealed_test.csv
During the submission period, only the most recent month of data will be used for the public leaderboard. Any test set data older than that will be published in revealed_test.csv, closely following the usual data release cycle for the micro business report. We expect to publish one copy of revealed_test.csv in mid-February. This file's schema will match train.csv.
census_starter.csv
Examples of useful columns from the Census Bureau's American Community Survey (ACS) at data.census.gov. The percentage fields were derived from the raw counts provided by the ACS. All fields have a two-year lag to match what information was available at the time a given microbusiness data update was published.
pct_bb_[year]- The percentage of households in the county with access to broadband of any type. Derived from ACS table B28002: PRESENCE AND TYPES OF INTERNET SUBSCRIPTIONS IN HOUSEHOLD.cfips- The CFIPS code.pct_college_[year]- The percent of the population in the county over age 25 with a 4-year college degree. Derived from ACS table S1501: EDUCATIONAL ATTAINMENT.pct_foreign_born_[year]- The percent of the population in the county born outside of the United States. Derived from ACS table DP02: SELECTED SOCIAL CHARACTERISTICS IN THE UNITED STATES.pct_it_workers_[year]- The percent of the workforce in the county employed in information-related industries. Derived from ACS table S2405: INDUSTRY BY OCCUPATION FOR THE CIVILIAN EMPLOYED POPULATION 16 YEARS AND OVER.median_hh_inc_[year]- The median household income in the county. Derived from ACS table S1901: INCOME IN THE PAST 12 MONTHS (IN 2021 INFLATION-ADJUSTED DOLLARS).

DATA STATS
Importing Libraries
Load Dataset


DATA TRANSFORMATION
The analysis primarily revolves around the first_day_of_month column present in both the Test Data and Revealed Test Data. The Test Data includes the values for which our model will generate predictions, while the Revealed Test Data contains the corresponding microbusiness density data provided for that specific period.
To ensure data consistency and avoid any overlap, we will examine the unique values present in the first_day_of_month column of both datasets. Subsequently, we will remove all rows from the Test Data that are also present in the Revealed Test Data. This step is essential to ensure that our model's predictions align with the available ground truth microbusiness density values provided in the Revealed Test Data.



In order to obtain the most recent value of the ACTIVE column for each CFIPS (County Federal Information Processing System) in the train Data, we will perform a group-by operation. By grouping the data based on the CFIPS column, we can retrieve the last recorded count of micro-businesses in each county.

To incorporate an additional feature into our model and add dimensionality to the test data, we will merge the 'last_active' column obtained earlier with the Test Data. Since the Test Data does not have an 'active' column, this merging process allows us to include the last recorded micro-business count as a new feature for our model.

To simplify the analysis of the census_starter dataset and streamline the merging process, we will combine the Train and Test datasets. As part of this merging process, we will introduce an additional column called is_test to distinguish between the Test and Train data. This column will serve as a flag to identify the origin of each observation.
By merging the Train and Test datasets, we can effectively study the census_starter dataset with reduced complexity. This consolidation step allows us to examine the combined data more comprehensively and prepare for subsequent stages where we merge all the available datasets before applying the model.

After merging the Train and Test datasets into the merged DataFrame called data, we will proceed to check for any missing values in this consolidated dataset. If any missing values are identified, we will perform imputation using a logical approach.
Our goal is to ensure that the dataset is complete and does not contain any missing values. By implementing an appropriate imputation logic, we can fill in the missing values with appropriate substitutes or estimates, thereby preserving the integrity of the data for further analysis.

We have observed that the missing values in the county and state columns exactly correspond to the number of values present in the Test Data. This occurrence is expected because the Test Data does not contain the county and state columns during the merging process. As a result, these columns in the merged dataset have missing values that match the count from the Test Data.
Furthermore, it is worth noting that the microbusiness_density column has a count of 18,810 missing values. This is because this column serves as the target variable that we will be predicting, and thus the missing values represent the instances for which we need to make predictions.
Overall, these missing value counts are in line with the expected data merging and prediction process, so we will impute County and State using the “group by” function based on the CFIPS column. In addition, let’s also create some more features.

Now let’s begin our analysis for the census_starter dataset which we have stored in a data frame called cs

To gain insights into the distribution, skewness, and nature of the data present in the cs dataframe, we can utilize the KDEPLOT and PROBPLOT functions. These visualizations will provide us with an understanding of the data's distribution and help confirm whether it follows a normal distribution.
KDEPLOT stands for kernel density estimation plot, we can visualize the shape of the distribution and also provide an estimation of the probability density function of the data.
Additionally, The PROBPLOT function generates a probability plot, also known as a Q-Q plot. It helps us assess if the data aligns with the expected pattern of a normal distribution or if it deviates significantly.
These visualizations will help us gain insights into the distribution characteristics, identify any potential skewness, and whether we can assume a normal distribution for the data.

After we run the above code, we get the following result and this is just for one of the features present in the census_starter dataset, In a similar way, we can observe the result for every feature.

When I analyzed the distribution of kdeplot and Q-Q plot of all the features present in the census_starter dataset, I could notice that most of the features are not normally distributed and there’s a high level of skewness present in the data.
Usually, when we deal with high levels of skewness and kurtosis present in the data, the best way to move forward is to perform a transformation that makes the features as close as to being normally distributed.
There are several methods to achieve the desired Normal Distribution state and that can include adding additional values (such as 1, 0.01, 0.001, etc) to the entire data and then taking Log(P), Log(1+P), SQRT(P), SQRT(Log(1+P)).
However, there’s an easy way to achieve the desired result using a machine learning technique called Box-Cox transformation.
Box-Cox transformation is a statistical technique that transforms your target variable so that it resembles a normal distribution.
Here’s how we can implement it.

Now let’s visualize the features again so that we can compare their distribution before and after transformation.
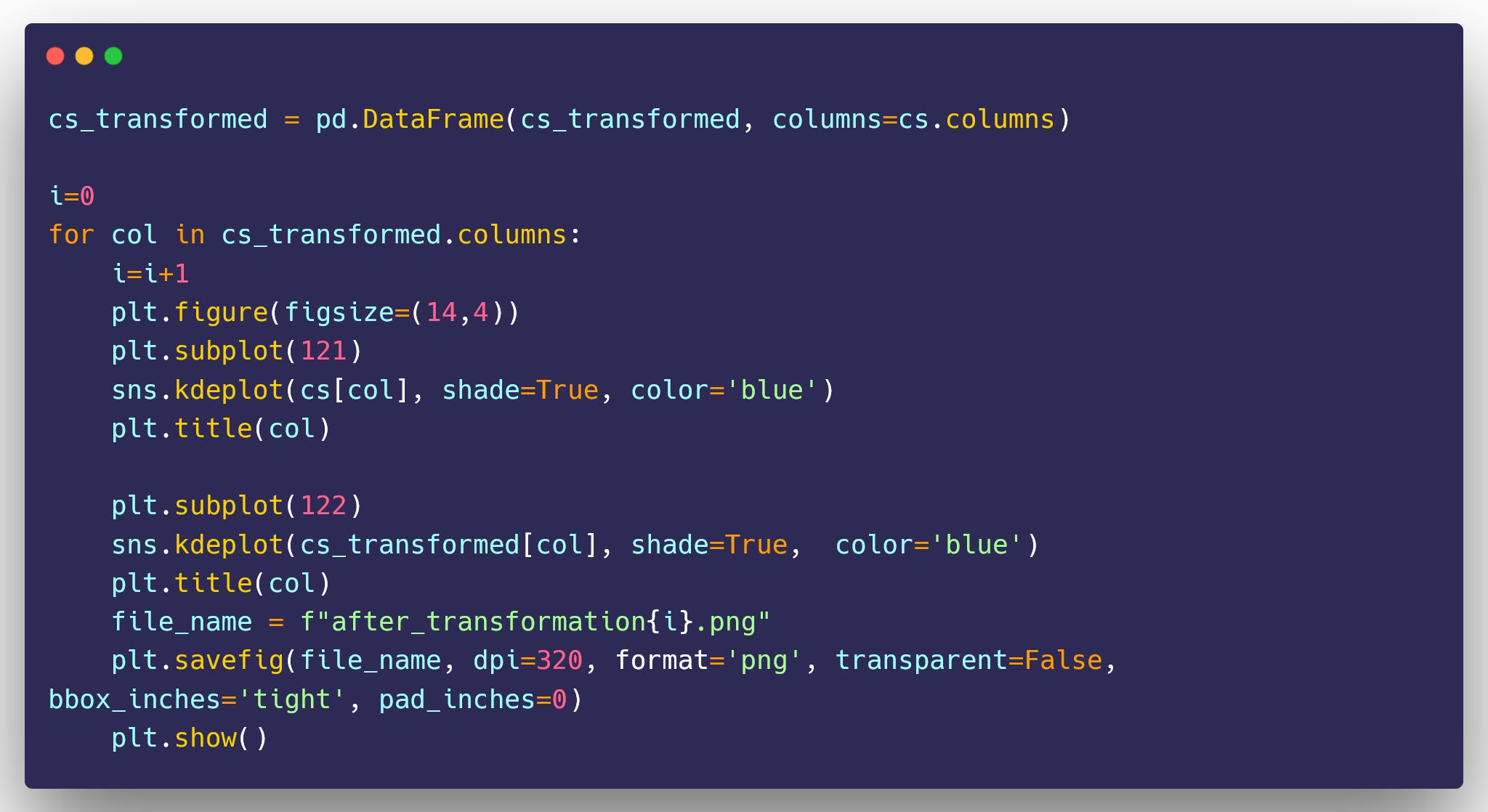
The above code will produce a before and after comparison of the distribution of features. Let me share an example of how it looks. This is for the variable called pct_foreign_born_2000 in the census_starter data.

Upon observing the plot, you can notice that the data distribution displays a significant amount of skewness. However, after applying the Box-Cox transformation, a notable transformation of the variable can be observed, resulting in a more normally distributed feature.
Due to the transformation, the CFIPS column also went through the transformation and we don’t want it. It is a good practice to leave out the column before transforming, however, I didn’t so I will do it now.
Now that we are done with completing Data Preprocessing and Data Transformation on our data, Let’s begin with our Training the Model process.
TRAINING AND TESTING THE MODEL
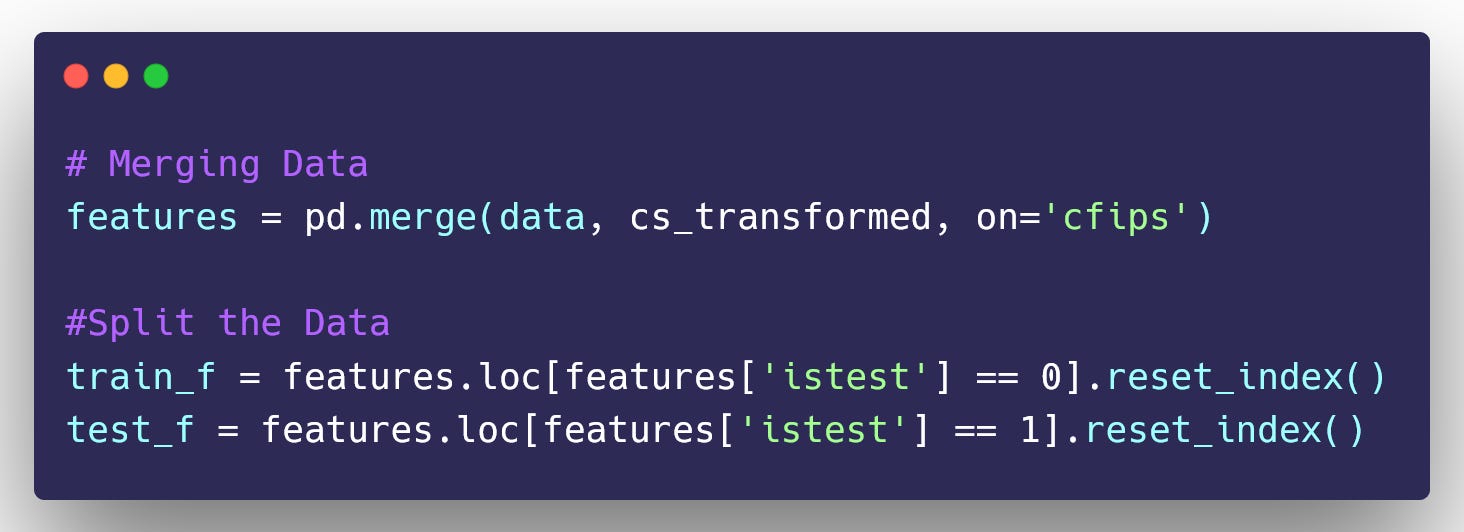
Now for the model training process, we will merge all available datasets into a single dataset. This combined dataset will include the Train Data, Test Data, and any additional relevant data such as the census_starter dataset. By merging all of the data, we can ensure that our model is trained on a comprehensive and representative dataset.
Once the data is merged, we will proceed to split it into Train Data and Test Data. This split will enable us to use the Train Data for model training, while the Test Data will be utilized for model evaluation and performance assessment.
Upon further analysis, I realized that I had overlooked the distribution of the target variable in the merged dataset. It became apparent that the distribution of the target variable, microbusiness_density, was not ideal and required transformation. This could potentially introduce bias into the resulting model's predictions for Microbusiness Density Forecasting.
To ensure the accuracy and fairness of the model, Applying an appropriate transformation technique to the target variable will help normalize its distribution and avoid any biases that may arise in the trained model.

After transformation, I could observe the following result and the difference is quite visible.
Original Distribution of Microbusiness Density column

Distribution of Microbusiness Density column after transformation
(np. sqrt(np.log1P(microbusiness_ensity))

Training Data


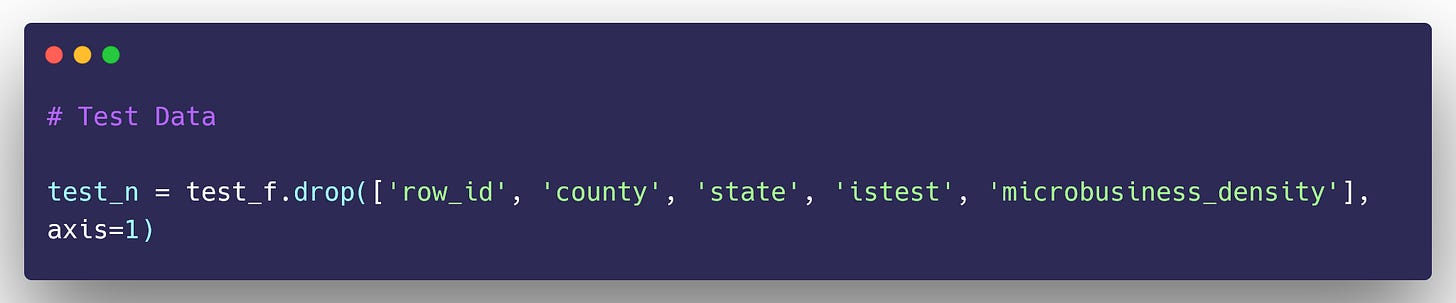
Testing Data

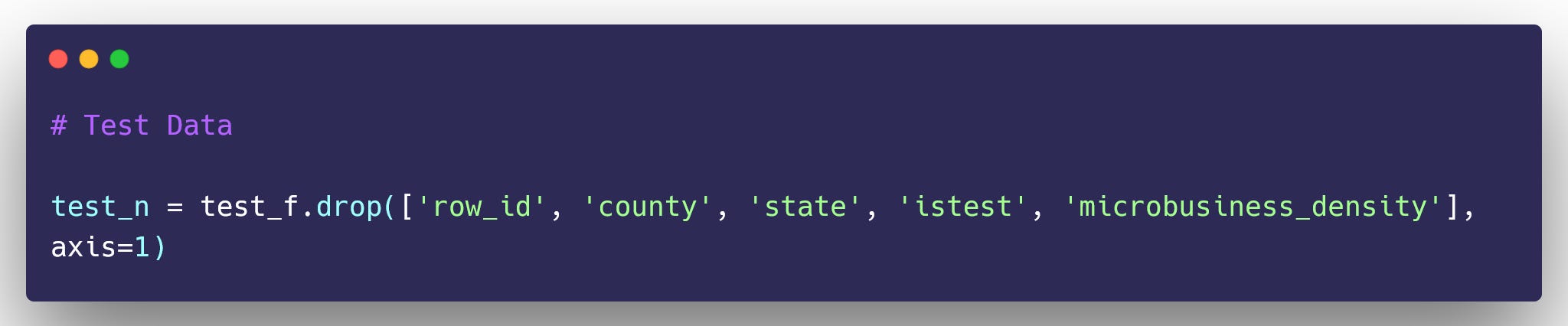
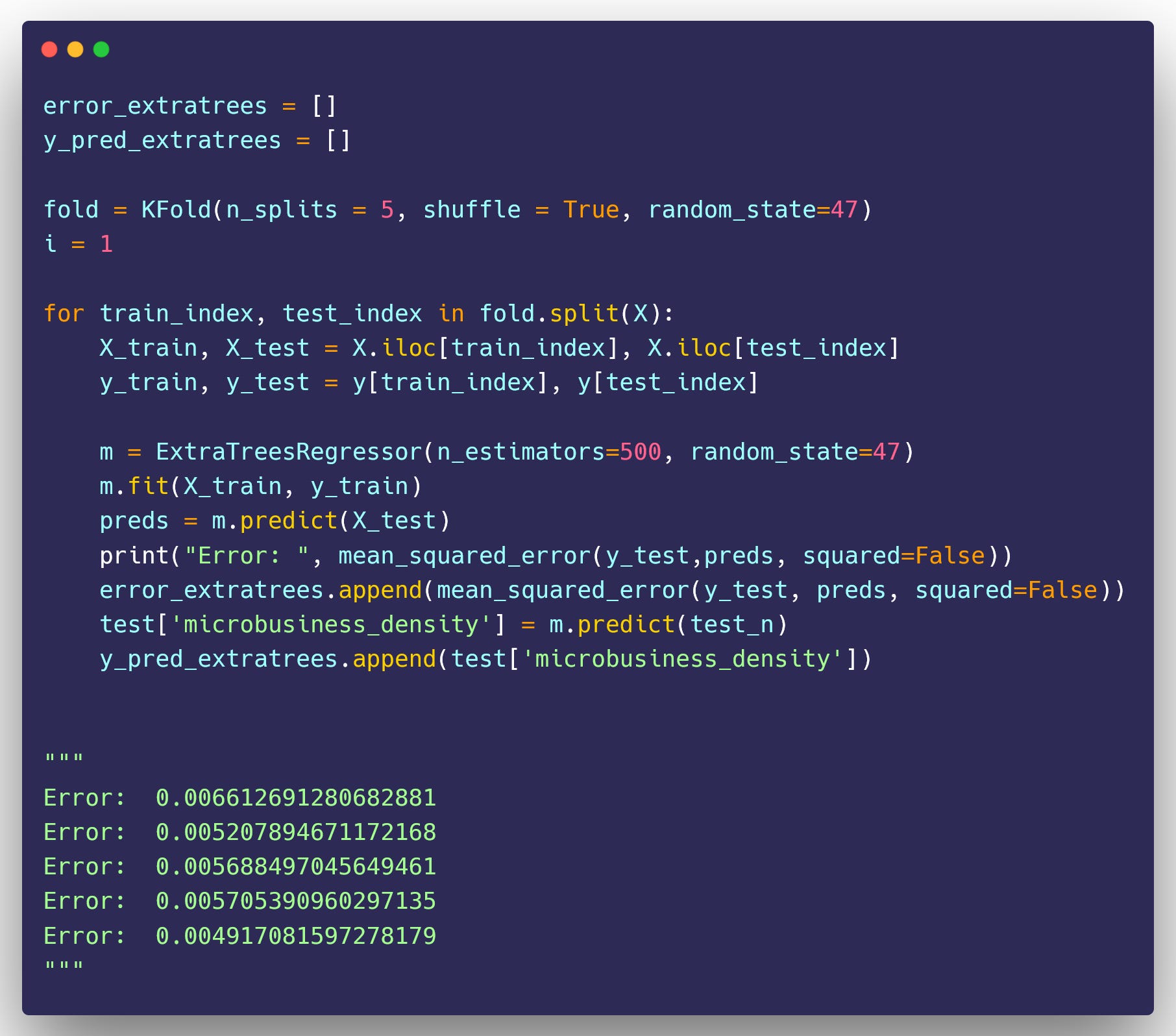
Model Training and Prediction






Final Result

Everything shared with you today is what it took me to get my notebook to achieve a decent position in the Kaggle competition - GoDaddy Microbusiness Density Forecasting, placing in the Top 24%.

I am grateful for your support for Hustle Data, and I am excited about this journey and will continue sharing my personal experiences with Data and insights every Saturday. Stay tuned for more exciting discussions and updates. Thank you!