

Unleashing the Power of Dask: Conquer Data at Lightning Speed!
Imagine by the time you finish reading this article you have already learned the art of leveraging Dask for data pre-processing, manipulation, and cleansing.

Hello, Legends!
I may not possess the mystical powers of a tech genius or have the audacity to claim mastery over every single topic that falls under the realm of those recent Buzzword Bonanzas that everyone's losing their minds over. For I am just a humbled Data Engineering Intern whose company happened to be a part of Fortune 500 Companies. I have a passion for Data and money is good too. But hey, let's not get ahead of ourselves; I'm just a humble soul, taking life one day at a time. Now, let's dive into this issue and witness the magic unfold! where we dive into the exciting world of data preprocessing and manipulation. Today, I am thrilled to introduce you to an amazing open-source Python library that will revolutionize the way you handle large-scale data processing: Dask!

What is Dask?
Dask is a powerful Python library designed for parallel computing. It enables you to scale your Python code seamlessly, from your trusty multi-core local machine to enormous distributed clusters in the cloud. With Dask, you can effortlessly tackle even the most massive datasets with lightning-fast speed and efficiency.
Why Dask?
Picture this: you've got a dataset that's too big to fit into memory on your local machine. Or perhaps your code is taking forever to complete because it's not utilizing your machine's full potential. That's where Dask swoops in to save the day! By harnessing the power of parallelism, Dask allows you to process data in chunks, breaking down complex tasks into manageable pieces that can be executed concurrently. This means you can significantly speed up your computations, unlocking new data exploration and analysis possibilities.
I don’t wanna delve more into talking about Dask documentation rather I would like to present my findings in a way that gets you working with the dataset when you finish reading this. If you're familiar with Pandas and Numpy, working with Dask will be a breeze.
Dask Installation
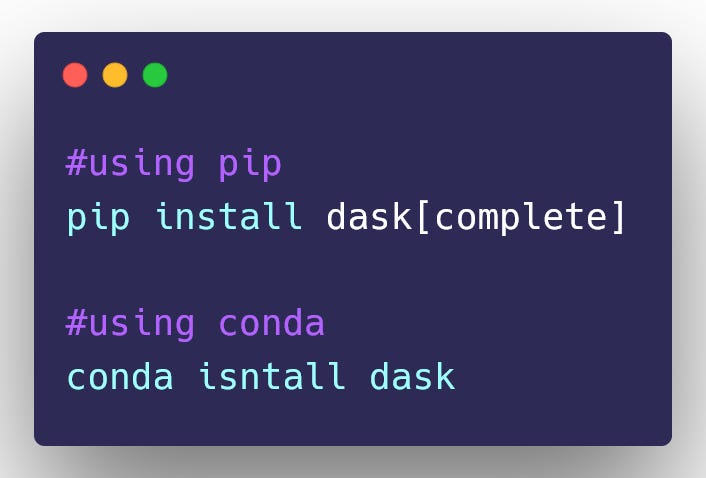
The easiest way to install Dask is by using PIP or CONDA package manager.
The dataset which we will be using can be found on Kaggle - NYC Parking Ticket Dataset
Importing Libraries
Pandas WALL TIME to load this dataset

Dask WALL TIME to load this dataset

This is something that intrigued me about creating this post, did you notice the WALL TIME difference between Pandas and Dask? Dask loads the dataset by parallel computation and dividing the dataset into partitions. There’s a way to check the number of partitions our data was divided into.

This dataset was divided into 33 partitions to load it faster.
View DataFrame and Features available in the dataset

This action is same as that in Pandas.
DataFrame Shape
Getting the shape of Data is a bit tiring in Dask, as when you run .shape function it just gives you the number of columns, and then to get the number of rows, you gotta be more technical.

Check the Datatypes of each feature

Description of the data in the DataFrame
It is same as .describe function as it is in Pandas.

Compute the Max value in a column

Accessing Single or Multiple columns in DataFrame

Dropping Single or Multiple Columns

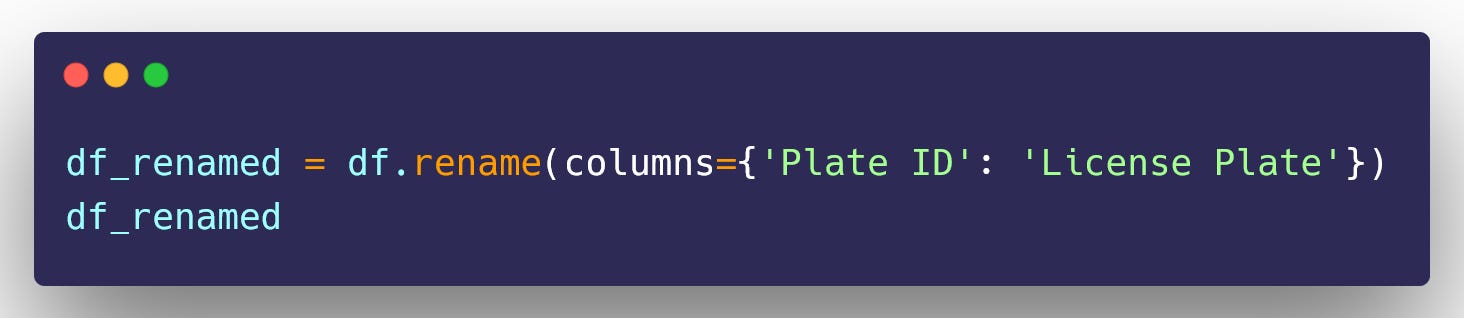
Renaming a Column
Getting single row or sequential slice of rows by index

Filtering a slice of rows using Dask and Pandas
Missing values count
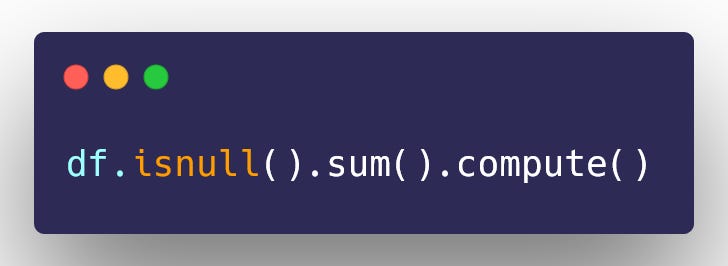
Calculate the percentage of missing values by column

Dropping Columns that have more than 50% missing values

Getting a unique value count in a column

Impute missing value with the most common color

Impute with a specific value

Impute using a specific method

As we conclude this inaugural issue, I assure you that the journey has only just begun. Brace yourselves for a remarkable voyage filled with thrilling news, invaluable tools, cutting-edge techniques, and captivating books on Machine Learning, Data Science, and Artificial Intelligence. Stay tuned, for every week, I will be delivering these gems straight to your inbox, ensuring you stay ahead of the curve in this ever-evolving realm. Together, let us embark on this exhilarating quest for knowledge and innovation.